Содержание
Как посмотреть статистику на Авито | Как пользоваться Аналитикой спроса на Avito
Аудиоверсия этой статьи
Авито — одна из самых популярных площадок для развития бизнеса. Максим Оганов, основатель агентства интернет-маркетинга Oganov Digital и эксперт в бизнес-школе Авито, рассказывает, чем может быть полезен инструмент Аналитика спроса предпринимателю и как им пользоваться
Деловая среда
Платформа знаний и сервисов для бизнеса
Открыть ИП сейчас
Максим Оганов
– Руководитель агентства комплексного интернет-маркетинга «Oganov Digital»
– Сертифицированный авитолог
– Спикер на мепроприятиях от Деловая среда, Авито, Like Центр, eLama, Синергия и МинЭкономРазвития
– Эксперт и преподаватель в официальной бизнес-школе «Авито»
– Участник акселлераторов ФРИИ и СтартХаб
– Практикующий маркетолог с опытом более 8 лет.
Содержание
Возможности аналитики спроса и как ей пользоваться
Как анализировать статические данные
Как анализировать динамические данные
Чем аналитика спроса полезна бизнесу
🚀 Сервис для быстрого старта бизнеса
Зарегистрируйте бизнес удаленно и бесплатно — через сервис от Деловой среды
Подать заявку онлайн
Аналитика спроса на Авито — это инструмент, позволяющий продавцам:
анализировать активность посетителей сайта, которые ищут нужные товары по запросам;
просматривать количество объявлений в статике и динамике;
выбрать сферу деятельности на площадке и корректировать собственную стратегию продвижения на Авито.
Аналитика спроса помогает определиться с тарифом и понять, какие услуги по продвижению потребуются вашему бизнесу, ведь с высокой конкуренцией нужны услуги большей силы.
Инструмент будет полезен как начинающим предпринимателям, так и опытным продавцам. Любой пользователь Авито с тарифами «Расширенный» и «Максимальный» может посмотреть статистику спроса на товары отдельных категорий.
Возможности аналитики спроса и как ей пользоваться
Рассмотрим работу инструмента на примере категории «Электроника». Чтобы перейти к инструменту, зайдите в свой аккаунт Авито, перейдите в личный кабинет, нажав на иконку профиля.
После перехода в профиль вы увидите меню в левой части экрана. Найдите пункт «Аналитика спроса».
Теперь перед вами страница инструмента.
Все объявления можно сортировать по трем параметрам: регион, категория товара и период публикации (за месяц или за день). Статистика отображается по категориям и подкатегориям. Так, «Электроника» — это категория, объединяющая подкатегории: телефоны, аудио и видео, ноутбуки, товары для компьютера и др. Таким образом, мы можем видеть статистику категории «Электроника» в целом, а также статистику отдельных подкатегорий.
Рассмотрим работу инструмента на реальном примере. У предпринимателя Константина собственный магазин электроники, и он хочет использовать площадку Авито в качестве инструмента продаж:
проанализировать спрос;
выбрать тариф продвижения;
товары, которые стоит продвигать.
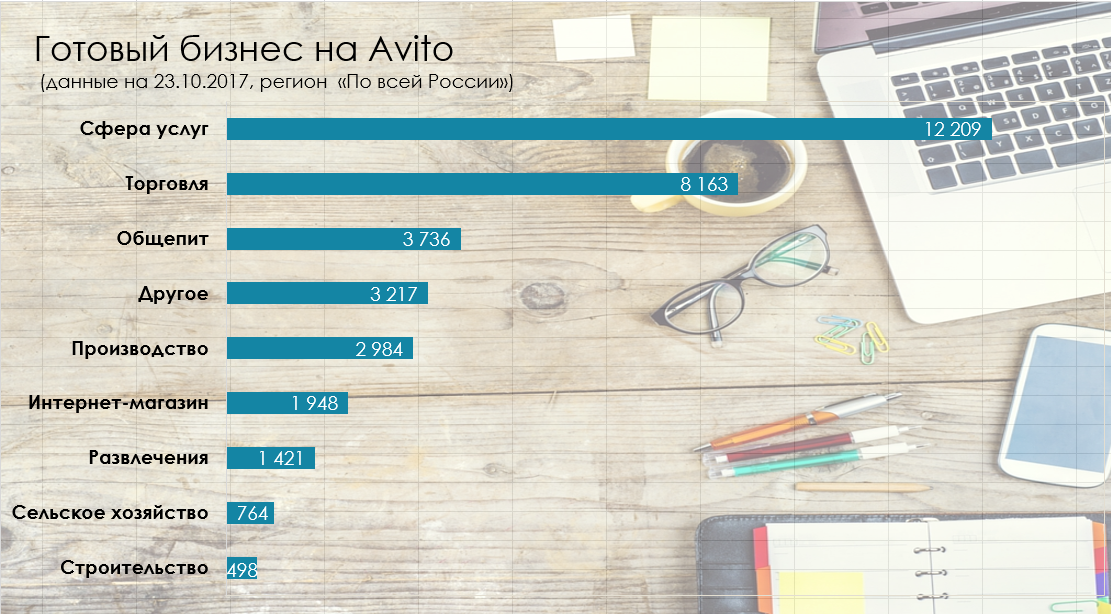
Для анализа спроса укажем регион Санкт-Петербург, категорию «Электроника», период — месяц. Получим следующую картину.
Как анализировать статические показатели
На снимке представлены численные показатели по данным: продавцы, объявления, просмотры, контакты и уровень спроса.
Продавцы — это физические и юридические лица, которые разместили хотя бы одно объявление в категории. Уровень конкуренции напрямую зависит от количества продавцов. Если конкуренция слишком высокая (ориентировочно — свыше 50 тыс. продавцов), потребуется платное продвижение или услуги авитолога, специалиста по продвижению на Авито.
Объявления — общее число объявлений на Авито в настоящий момент.
Контакты — количество заинтересованных пользователей — таких, которые написали или нажали кнопку «Показать номер».
Просмотры — количество посещений карточки.
Уровень спроса — отражает среднее количество покупателей на одно объявление в категории. Уровень спроса 3–5 считается высоким и говорит о популярности категории.
Наибольший интерес для аналитики представляют: количество объявлений, количество контактов и уровень спроса.
Количество объявлений — это общее число объявлений в указанной категории по заданным фильтрам. Этот показатель отражает общий уровень спроса и заполненности рынка теми или иными товарами. В примере видим, что общее число товаров в категории «Телефоны» — 165 392, а в категории «Аудио и видео» — 182 030.
📌 Совет
При анализе стоит учесть, что одно объявление может содержать в себе продажу сразу нескольких товаров. К видеокамере может продаваться чехол, штатив и другие аксессуары за дополнительную плату или комплект видеокамер либо аудиотехники. Но бывает и обратное, когда один товар появляется в нескольких объявлениях. Такое можно наблюдать на примере продажи квартир.
Второе интересующее нас поле — контакты. Контакт отражается в статистике, когда потенциальный покупатель нажал кнопку «Показать номер» или начал диалог с продавцом. При этом, даже если пользователь совершил несколько действий, он считается одним контактом. Видим, что в категории «Телефоны» — 579 467 контактов, а в категории «Аудио и видео» — 279 541.
Следующий важный показатель — уровень спроса. Это отношение количества контактов к количеству объявлений в категории. Заметим, что в обеих рассматриваемых категориях он отличается: в среднем на каждое объявление в категории «Телефоны» приходится 3 контакта, а в категории «Аудио и видео» — 1.
Здесь стоит обратить внимание на то, что уровень спроса — это результат простого деления. Поясним: в категории могут быть заброшенные или некачественные объявления с завышенными ценами, а также очень привлекательные предложения, которые закрываются за считанные часы. Поэтому делать однозначные выводы относительно уровня спроса не стоит, но при оценке популярности категории этот показатель очень поможет.
Мы рассмотрели статические показатели данных. Этот вид данных позволяет оценить уровень спроса в категории за конкретный период — месяц или день. Особенно важными пунктами при анализе являются количество контактов, объявлений и уровень спроса.
На основе приведенных данных Константину рациональнее создавать объявления в категории «Телефоны», поскольку спрос здесь более высокий и обеспечит больший поток клиентов. Но чтобы составить полную картину, стоит обратиться и к динамическим показателям.
Как анализировать динамические показатели
Нажав на название категории «Телефоны», можно посмотреть подробную статистику в цифрах и аналитику спроса на графике, как на изображении ниже.
По графику становится ясно — уровень спроса на телефоны был на среднем уровне на протяжении 2021 года и начал повышаться в феврале 2022-го, достигнув пиковых значений в марте. Сейчас спрос возвращается к своему прежнему состоянию.
Перейдем в категорию «Аудио и видео».
Здесь видим, что уровень спроса в разы ниже, где пиковое значение — 1,93. Однако динамика прослеживается похожая: резкий скачок уровня спроса в марте и затем его стабилизация к прежним значениям.
В этом примере Константину стоит ориентироваться на статические показатели, поскольку динамические не показывают четкой картины. Вероятнее всего, пиковое значение спроса в марте в обеих категориях связано с внешними временными факторами.
📌 Совет
Уровень спроса в динамике может быть полезен в случае сравнения двух разных направлений, например «Средства гигиены» и «Ноутбуки». Но случается и так, что динамика отличается в категориях одного направления, поэтому анализ в любом случае необходим.
Среди рассмотренных категорий наиболее перспективной для размещения объявлений будет категория «Телефоны». Хотя в категории «Аудио и видео» больше объявлений, количество контактов здесь значительно ниже, что и определяет более низкий уровень спроса. Среднее число контактов в категории «Телефоны» — 3 человека на объявление. Это говорит о том, что посетители заинтересованы в этом виде товаров, то есть чаще ищут их по запросам, следовательно, шансы на успешные продажи повышаются.
🚀 Сервис для быстрого старта бизнеса
Зарегистрируйте ИП или ООО без визита в налоговую и пошлины — через сервис от Деловой среды
Подать заявку онлайн
Чем аналитика спроса полезна бизнесу
Аналитика спроса — это удобный, а главное, полезный инструмент при работе с площадкой Авито.
С помощью аналитики спроса можно увидеть:
какие товары сезонные,
на какие растет спрос,
какие постепенно уходят с рынка.


Сезонные товары отслеживаются по динамическим данным — кривая спроса будет повышаться в определенный сезон. Рост спроса сопровождается повышением кривой ближе к настоящей дате, а спад — снижением кривой.
Аналитика позволит выбрать нужную категорию товара, если вы только планируете начать свой бизнес на Авито, а также оценить уровень конкуренции в своей категории и составить грамотную стратегию продвижения на Авито — определить количество объявлений и их структуру, выбрать услуги по продвижению.
Статьи
10 советов предпринимателям, как успешно продавать на маркетплейсах
Выбор ниши
Статьи
Как привлекать клиентов через маркетплейсы услуг
Соцсети
Статьи
5 ошибок предпринимателей на сервисах объявлений. Гид по эффективным продажам
Продвижение в Интернете
Стало известно, что россияне чаще всего ищут на «Авито»
https://ria.ru/20200122/1563704263. html
html
Стало известно, что россияне чаще всего ищут на «Авито»
Стало известно, что россияне чаще всего ищут на «Авито» — РИА Новости, 03.03.2020
Стало известно, что россияне чаще всего ищут на «Авито»
Россияне в 2019 году чаще всего искали на площадке для размещения объявлений «Авито» квартиры, велосипеды и дома, сообщили РИА Новости в пресс-службе сервиса. РИА Новости, 03.03.2020
2020-01-22T06:46
2020-01-22T06:46
2020-03-03T19:07
общество
россия
/html/head/meta[@name=’og:title’]/@content
/html/head/meta[@name=’og:description’]/@content
https://cdnn21.img.ria.ru/images/150950/32/1509503263_0:0:2867:1613_1920x0_80_0_0_7c23f6c10103e3e4283cf212adb0940f.jpg
МОСКВА, 22 янв — РИА Новости. Россияне в 2019 году чаще всего искали на площадке для размещения объявлений «Авито» квартиры, велосипеды и дома, сообщили РИА Новости в пресс-службе сервиса.Аналитики «Авито» проанализировали запросы пользователей по итогам прошлого года, введенные в поисковой панели, и сравнили их с запросами в 2018 году. Однако популярнее домов в рейтинге запросов в прошлом году были велосипеды — они заняли второе место, как и в 2018 году. «Пользователи также больше интересовались обстановкой жилища, чем в 2018 году: на четвертом месте оказался запрос «диван», который поднялся в рейтинге на шесть позиций, а 12-е место заняли кровати, которые в прошлом году находились на 14-м», — отметили в сервисе. На пятом месте значится телефон.В то же время несколько снизилась популярность техники для дома. Так, холодильники и телевизоры опустились в рейтинге на два пункта каждый, заняв шестое и десятое места соответственно. «Авито» отмечает и снижение интереса россиян к автомобилям.»Позиция работы осталась неизменной — седьмое место. При этом из рейтинга выбыло связанное с поиском работы слово водитель, которое в прошлом году находилось на 12-м месте по числу запросов», — добавили в сервисе.
Однако популярнее домов в рейтинге запросов в прошлом году были велосипеды — они заняли второе место, как и в 2018 году. «Пользователи также больше интересовались обстановкой жилища, чем в 2018 году: на четвертом месте оказался запрос «диван», который поднялся в рейтинге на шесть позиций, а 12-е место заняли кровати, которые в прошлом году находились на 14-м», — отметили в сервисе. На пятом месте значится телефон.В то же время несколько снизилась популярность техники для дома. Так, холодильники и телевизоры опустились в рейтинге на два пункта каждый, заняв шестое и десятое места соответственно. «Авито» отмечает и снижение интереса россиян к автомобилям.»Позиция работы осталась неизменной — седьмое место. При этом из рейтинга выбыло связанное с поиском работы слово водитель, которое в прошлом году находилось на 12-м месте по числу запросов», — добавили в сервисе.
https://ria.ru/20190916/1558716531.html
россия
РИА Новости
1
5
4.7
96
internet-group@rian. ru
ru
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
2020
РИА Новости
1
5
4.7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
Новости
ru-RU
https://ria.ru/docs/about/copyright.html
https://xn--c1acbl2abdlkab1og.xn--p1ai/
РИА Новости
1
5
4.7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
1920
1080
true
1920
1440
true
https://cdnn21.img.ria.ru/images/150950/32/1509503263_74:0:2805:2048_1920x0_80_0_0_55bd72c47f82ed7bbf62bcbc937db09c.jpg
1920
1920
true
РИА Новости
1
5
4.7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og. xn--p1ai/awards/
xn--p1ai/awards/
РИА Новости
1
5
4.7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
общество, россия
Общество, Россия
МОСКВА, 22 янв — РИА Новости. Россияне в 2019 году чаще всего искали на площадке для размещения объявлений «Авито» квартиры, велосипеды и дома, сообщили РИА Новости в пресс-службе сервиса.
Аналитики «Авито» проанализировали запросы пользователей по итогам прошлого года, введенные в поисковой панели, и сравнили их с запросами в 2018 году.
«Квартира в очередной раз стала самым популярным поисковым запросом. Также в прошлом году россияне активно искали дома», — сказали в компании. Годом ранее дома находились лишь на шестом месте.
Однако популярнее домов в рейтинге запросов в прошлом году были велосипеды — они заняли второе место, как и в 2018 году. «Пользователи также больше интересовались обстановкой жилища, чем в 2018 году: на четвертом месте оказался запрос «диван», который поднялся в рейтинге на шесть позиций, а 12-е место заняли кровати, которые в прошлом году находились на 14-м», — отметили в сервисе. На пятом месте значится телефон.
На пятом месте значится телефон.
В то же время несколько снизилась популярность техники для дома. Так, холодильники и телевизоры опустились в рейтинге на два пункта каждый, заняв шестое и десятое места соответственно. «Авито» отмечает и снижение интереса россиян к автомобилям.
«Позиция работы осталась неизменной — седьмое место. При этом из рейтинга выбыло связанное с поиском работы слово водитель, которое в прошлом году находилось на 12-м месте по числу запросов», — добавили в сервисе.
16 сентября 2019, 03:53
Стало известно, какую услугу россияне все чаще ищут на «Авито»
Система управления метаданными в Авито | Фрол Крючков | AvitoTech
Каждая классификация в какой-то момент своего роста сталкивается с проблемой систематизации, упорядочивания и организации своих метаданных. Почему это так важно? Чтобы ответить на этот вопрос, нам нужно понять несколько основных вещей о метаданных и о том, как они используются.
Скорее всего, вы уже работали с метаданными. Я приведу короткий пример, чтобы вы могли получить представление. Предположим, у вас есть сайт, на котором пользователи могут публиковать информацию о том, что они продают. Чтобы разместить рекламу, продавец заполняет определенные поля, такие как заголовок , категория , цена , местоположение, и т. д. Эти поля, значения списка и типы значений, которые могут заполнять пользователи, являются метаданными. Проще говоря, это данные о данных.
Я приведу короткий пример, чтобы вы могли получить представление. Предположим, у вас есть сайт, на котором пользователи могут публиковать информацию о том, что они продают. Чтобы разместить рекламу, продавец заполняет определенные поля, такие как заголовок , категория , цена , местоположение, и т. д. Эти поля, значения списка и типы значений, которые могут заполнять пользователи, являются метаданными. Проще говоря, это данные о данных.
Рисунок 1. Примеры метаданных: название, категория, цена, описание объявления
После того, как продавец подал объявление, ему необходимо оплатить листинг. Эти листинговые сборы обычно основаны на информации в объявлении. Например, цена автомобиля может существенно различаться в зависимости от года выпуска и марки. Или это может быть местоположение, которое больше всего влияет на листинговые сборы. Не очевидно, что скорость и плавность изменения метаданных компании станут узким местом для поиска стратегий монетизации путем проведения A/B-тестов.
Рисунок 2. Использование метаданных в бизнесе
Менее очевидный пример — когда метаданные помогают настроить SEO. Не секрет, что чем больше органического трафика у сайта, тем лучше для бизнеса. Страницы результатов поисковой системы (SERP) и рекламные страницы являются самыми популярными страницами в объявлениях. Рекламные страницы менее интересны, поэтому я опишу случай SERP.
Пользователи могут использовать миллионы комбинаций фильтров. Каждая комбинация фильтров дает уникальную поисковую выдачу. И это плохо для SEO, когда тонны поисковых запросов пользователей разбросаны по тоннам поисковой выдачи, потому что вес каждой страницы мал. Чтобы решить эту проблему, появился канонический URL.
Один уникальный канонический URL группирует относительно похожие страницы и заставляет их считаться одной страницей для поисковых систем. Например, пользовательский поиск по всем автомобилям старше пяти лет попадет в один канонический URL «5-year-old-car», даже если пользователь укажет конкретную марку или цвет. Или критерий поиска: «дом напротив пляжа» с дополнительным фильтром типа коттедж или квартира значения не имеет; это будет «перед пляжем». Это простые примеры, но я думаю, что вы поняли идею. Повторюсь: чем быстрее ваша система позволит вам адаптироваться к меняющемуся миру, тем лучше.
Или критерий поиска: «дом напротив пляжа» с дополнительным фильтром типа коттедж или квартира значения не имеет; это будет «перед пляжем». Это простые примеры, но я думаю, что вы поняли идею. Повторюсь: чем быстрее ваша система позволит вам адаптироваться к меняющемуся миру, тем лучше.
На этом этапе вы можете применить один и тот же шаблон ко всем следующим полям:
- какие данные должен предоставить пользователь;
- какой тип метаданных, отображаемых в рекламе, приводит к лучшему CTR;
- обнаружение мошеннических списков;
- индексация;
- ценовое предложение;
- вы называете это.
Мы обсудили преимущества быстрого изменения метаданных. Но что мешает быстро изменить его?
Из рисунка 2 видно, что метаданные объединяют все домены приложения. Вот почему трудно внести изменения в какую-либо его часть. Даже незначительные изменения типа атрибута могут сломать всю систему. Например, изменение одного атрибута из списка значений в форме подачи объявления может нарушить алгоритмы поисковой индексации и монетизации.
Мы хотели, чтобы разные отделы легко принимали решения относительно своих метаданных без взаимодействия с другими отделами. В то же время отделы должны при необходимости синхронизировать метаданные между разными доменами. Например, когда мы хотим добавить обязательное поле в определенную категорию, не нарушая индексацию поиска или удаляя поля, используемые при расчете платы за листинг. Помня об этом, мы определили функциональные требования к нашей системе управления метаданными или информационной модели, как мы ее называем.
Функциональные требования:
- Решение должно предоставлять нашим инженерам и аналитикам возможность легко вносить изменения в метаданные, такие как добавление, удаление и обновление атрибутов и категорий, а также их типов, значений и параметров.
- Любые изменения в метаданных пространства конкретного отдела не должны влиять на метаданные других отделов. Если это невозможно, мы должны предупредить пользователей. Например, атрибуты для добавления на десктоп, iOS и Android с разными версиями, пространство атрибутов для поисковой индексации, модерации, поисковых фильтров и визуализации на разных платформах.
- Каждый отдел (доменное пространство) должен иметь возможность запускать несколько версий своих метаданных одновременно, т. е. для целей A/B-тестирования.

Нефункциональные требования:
- Система должна легко масштабироваться по горизонтали.
- Он должен эффективно использовать память и быть быстрым во время выполнения.
- Должна быть терпима к несоответствию версий.
- Удобно для работы в сети.
Самый простой способ хранить метаданные — встроить их в схему базы данных и жестко закодировать в кодовой базе. Чтобы показать это, мы приступим к нашему первому примеру. После того, как пользователь отправил рекламу, она будет сохранена в таблице базы данных со следующей схемой:
Рисунок 3. Схема таблицы для хранения рекламы
Не поймите меня неправильно. В данном случае это совершенно прекрасный способ сделать вашу схему, и я почти уверен, что в большинстве случаев он достаточно хорош. Однако в нашем случае нам нужно запустить несколько разных категорий. Каждая категория — это целая вертикаль в нашем бизнесе, и каждая вертикальная команда хочет экспериментировать в своей категории, добавляя, удаляя, изменяя столбцы.
Каждая категория — это целая вертикаль в нашем бизнесе, и каждая вертикальная команда хочет экспериментировать в своей категории, добавляя, удаляя, изменяя столбцы.
Мы также хотим провести A/B-тестирование, добавив новое поле в определенную категорию, чтобы узнать, понравится ли оно пользователям. Это не будет проблемой, если вам не нужно изменить схему и добавить новое поле, что требует блокировки всей таблицы. Это довольно сложно, если вы запускаете базу данных с миллиардами рекламных объявлений. Даже если вы сегментируете базу данных по категориям, вам все равно потребуется выполнить миграцию, установить значения по умолчанию и т. д. Вторая проблема заключается в том, что для изменения вашей схемы требуется новая фиксация для изменения схемы базы данных и новое развертывание службы для выполнения миграции схемы. Это не та беглость, которую мы хотели.
Давайте представим один возможный способ организации схем базы данных, который не потребует от нас выполнения миграций для доставки новых атрибутов:
Рисунок 4. Вообразимое решение для динамических метаданных вокруг атрибутов рекламных объявлений
Вообразимое решение для динамических метаданных вокруг атрибутов рекламных объявлений
Ого, пять новых таблиц вместо одной, и еще пара не показаны для простоты. Но не бойтесь. Идея проста: мы превращаем наши столбцы в строки, а остальные — это вспомогательные таблицы для запуска системы. Этот подход называется Модель значения атрибута сущности (EAV) .
Так много новых таблиц в основном потому, что теперь наше приложение отвечает за обеспечение логической схемы. В старом подходе база данных отвечала за обеспечение согласованности данных с помощью внешних ключей. Подход EAV приводит нас к двум проблемам:
- Наше приложение должно отвечать за согласованность данных.
- При такой нормализованной схеме производительность во время выполнения сильно пострадает.
Другой подход заключается в использовании документно-ориентированного способа хранения структуры атрибутов и данных. Мы оспорили этот подход и пришли к выводу, что если бы мы сохраняли свойства и данные в каждом рекламном документе, это стоило бы нам слишком много памяти. И самое главное, работа со старыми документами в кодовой базе обременительна.
И самое главное, работа со старыми документами в кодовой базе обременительна.
Мы не рассматривали графовые базы данных из-за отсутствия опыта в нашей компании.
Основные идеи, использованные при разработке нашей информационной модели, устарели и хорошо зарекомендовали себя — нормализация для согласованности, денормализация для производительности. Мы пошли по этому пути и придумали два глобальных компонента:
- Система управления метаданными с дружественным пользовательским интерфейсом для управления вариациями шаблона EAV.
- Фронтенд для бэкенда — высокопроизводительные микросервисы, выполняющие операции с данными во время выполнения. Они используют сильно денормализованный интерфейс данных для внутренней системы для проверки, подготовки к рендерингу и других целей.
После формирования этих глобальных компонентов возник шаблон EAV: как обеспечить согласованность данных на уровне приложения и ускорить его работу во время выполнения.
Рисунок 5. Основные элементы инфомодели
Основные элементы инфомодели
Ядро системы инфомодели состоит из двух основных элементов. Первый — это каталог категорий, атрибутов, значений и возможных отношений. Второй — макет, абстракция, состоящая из трех других элементов, о которых мы поговорим позже.
Каталог
Каталог представляет собой нормализованное хранилище категорий, атрибутов и значений в третьей нормальной форме. Он отражает архитектуру шаблона EAV, рассмотренную ранее, но только его атрибутивную часть. В каталоге есть список категорий, который является корнем для остальных атрибутов. Это список категорий, в которых работает наш бизнес, таких как аренда автомобилей, продажа автомобилей, продажа недвижимости, аренда недвижимости, краткосрочная аренда недвижимости и другие.
Далее идет каталог атрибутов. Атрибуты являются свойством категории. Например, это может быть марка , модель , год выпуска на аренду автомобиля . Для недвижимости это может быть город , район, или площадь кв. Значения являются всеми возможными значениями атрибутов перечислимого типа. Например, для атрибута марка категории авто возможные значения: audi, bmw или ford .
Значения являются всеми возможными значениями атрибутов перечислимого типа. Например, для атрибута марка категории авто возможные значения: audi, bmw или ford .
Также каталог отвечает за все возможные отношения между атрибутами и их значениями:
Рисунок 6. Формат отношений между атрибутами и значениями
Чтобы объяснить, почему нам все же нужно сохранить все возможные отношения, нам нужно перейти ко второму основному компоненту инфомодели — макету .
Макет
Макет представляет собой композицию из трех различных компонентов.
Макет
Макет — это имя для трех манифестов, описывающих поведение, структуру и свойства пространства имен. Компоненты макета решают одну проблему, имеющую две стороны:
- Возможность по-разному представлять одни и те же метаданные в разных пространствах имен.
- Изоляция одного пространства имен от других, чтобы одна команда могла изменять любые свойства поведения, структуры и свойства формы, не затрагивая другие пространства имен.

Отношения отвечают за определенную структуру данных в пространстве имен или макете, как мы называем это внутри. Проще показать на примере с рисунка 7:
Рисунок 7. Пример двух структур отношений одних и тех же метаданных
Как видите, есть две пользовательские истории, в которых мы используем одни и те же метаданные в разных схемах.
Первый случай — подача нового объявления о продаже автомобиля. В этом потоке самым коротким способом для пользователя указать свой автомобиль будет сначала выбрать марку, затем выбрать модель этой марки, затем указать год выпуска автомобиля и так далее. По мере того, как пользователь заполняет поля, становится меньше вариантов для выбора. Мы можем даже заполнить остальные поля автоматически на каком-то шаге, потому что остается только один вариант.
Другой пример: посетитель ищет автомобиль. Они обычно ищут с более широким диапазоном. Таким пользователям проще заполнить марку и модель и выбрать из списка 4–8 поколений, чем подбирать конкретные годы. В таких сценариях в игру вступают отношения. Используя несжатую структуру каталога с картинки 6, мы можем настроить любые отношения компоновки. Эта идея также широко используется при проверке входных данных пользователя.
В таких сценариях в игру вступают отношения. Используя несжатую структуру каталога с картинки 6, мы можем настроить любые отношения компоновки. Эта идея также широко используется при проверке входных данных пользователя.
Форма полей. Следующим элементом макета является форма полей. Этот компонент представляет собой декларативный способ описания полей, отображаемых для пользователя или для внутреннего бэкэнда.
Форма состоит из списка полей, которые связаны с определенными отношениями и атрибутами. Важно то, что здесь объявлены все конфигурации полей. Это означает, что семантически один и тот же атрибут может иметь разные свойства в разных макетах. Например, у нас есть атрибут бренда, и когда пользователь отправляет рекламу, поле выглядит как вход для выбора одной опции. Однако в форме поиска это поле с несколькими вариантами. Форма отвечает за:
- Список полей атрибутов формы.
- Связь между полями и фактическими атрибутами формы и каталогом.
- Свойства полей и самой формы.

Правила. Последний элемент макета — это манифест правила. Это декларативный DSL (предметно-ориентированный язык) для описания поведения полей формы. Этот компонент отвечает за отображение/скрытие, включение/отключение, проверку полей на основе состояния всей формы и даже изменение их свойств и состояний.
Вы можете увидеть результат этого элемента при выборе марки. Он запускает новое состояние формы, когда мы отображаем атрибут модели. Или другой пример, когда в выбранном городе есть метро, мы покажем атрибут со станциями метро. Стоит отметить, что манифесты никто не пишет. Система управления метаданными создает их автоматически в пользовательском интерфейсе.
Управление версиями
Макеты — отличный способ различать разные платформы, домены и отделы. Однако, когда у каждого отдела есть свой набор макетов, они быстро понимают, что хотят запускать несколько версий одного и того же макета одновременно для A/B-тестов или когда мы объединяем старые версии мобильных приложений или внутренних сервисов.
Реализация управления версиями макетов концептуально ничем не отличается от системы контроля версий, такой как Git. Он использует систему ветвления. У нас есть сущности, которые могут меняться: каталоги и макеты (правила, отношения, формы). Мы также знаем, что у нас должна быть возможность запускать столько версий одного и того же макета, сколько у нас есть A/B-тестов.
Это приводит нас к реализации, в которой у вас есть ветки для различных A/B-тестов. Но чтобы использовать конкретную ветку, включая основную ветку, вы должны ее освободить. В момент релиза происходят две основные вещи.
Во-первых, серверная часть объединяет все изменения и выводит их в эффективный формат хранения, к которому можно легко получить доступ во время выполнения. Во-вторых, выпуск тега версии, сгенерированного для того, какая версия макета может быть доступна в производстве. Чтобы поддерживать актуальность метаданных A/B-тестов, вы можете объединить основную ветвь. Слияние основной ветки с A/B-тестированием необходимо, так как вы поддержали все объекты после выпуска версии метаданных, включая те, которые вы даже не трогали. Это происходит потому, что мы решили реализовать стратегию только добавления, которая требует менее сложной реализации.
Это происходит потому, что мы решили реализовать стратегию только добавления, которая требует менее сложной реализации.
Маршрутизация
Прежде всего, что такое маршрутизация? Мы уже обсудили множество элементов, таких как версии и макеты. Маршрутизация была придумана для того, чтобы клиент (мобильное приложение, фронтенд-браузер, фронтенд-сервис) мог указать макет и версию для его использования.
Технически маршрутизация — это просто строка, по которой другие службы могут получить доступ к макетам. Он имеет шаблон: {версия}.{имя макета}.{категория}. В реальной жизни это выглядит так: REAL-123.new-adv-mobile.13. Тег версии обычно обозначает задачу Jira, в которой запрашиваются изменения. Однако, если вы хотите отладить макет в промежуточной версии, не выпуская новую версию, вы можете указать dev.real-123 в качестве имени тега. Тогда все спецификации будут генерироваться по запросу. Я не буду обсуждать, как это делается в этой статье, потому что это совсем другая тема.
Рисунок 8. Маршрутизация
Здесь менее очевидное наблюдение: наличие категории в маршруте обеспечивает максимальную степень детализации A/B-тестов. Это сделано специально. У каждого отдела или бизнес-вертикали есть своя «песочница» для проведения экспериментов без дублирования с другими отделами. Однако внутри маршрута все конфликтующие A/B-тесты должны быть соответствующим образом организованы внутри одного отдела.
Одна из основных целей новой системы управления метаданными заключалась в том, чтобы убедиться, что мы можем легко вносить новые изменения, в том числе несовместимые с предыдущими версиями. Это невозможно, если серверная часть обслуживает последнюю версию, потому что это приводит к тому, что мы предоставляем новую версию конечной точки для критических изменений. Огромной архитектуре сложно перейти на следующую версию API. Поэтому мы решили изменить эту парадигму и предоставить клиентам ту версию, которую они хотят.
Поскольку мы рассмотрели все компоненты, пришло время показать всю концепцию. Для этого я воспользуюсь аналогией с призмой. По крайней мере, это работает для меня, и я надеюсь, что это сработает и для вас. Итак, у вас есть золотой источник ваших каталогов метаданных. Также у вас есть макеты, которые представляют собой набор правил, форм и отношений. Идея довольно проста: различные макеты подобны призме, которая фильтрует и изменяет представление и поведение золотого источника каталогов.
Для этого я воспользуюсь аналогией с призмой. По крайней мере, это работает для меня, и я надеюсь, что это сработает и для вас. Итак, у вас есть золотой источник ваших каталогов метаданных. Также у вас есть макеты, которые представляют собой набор правил, форм и отношений. Идея довольно проста: различные макеты подобны призме, которая фильтрует и изменяет представление и поведение золотого источника каталогов.
Рисунок 9. Макеты как призма для определенных бизнес-доменов
Есть несколько важных вещей, которые макеты делают и не делают:
- Макет не отвечает за внешний вид форм. Он содержит структуру в виде шагов и свойств полей. Но он действует как конфигурация для интерфейса.
- Макет не всегда служит визуальным представлением чего-либо. Макет может быть механизмом проверки, представлением данных для внутреннего использования и т.п. Кроме того, макет может выступать в качестве механизма шаблонов для канонических URL-адресов поисковой выдачи.
- Одновременно можно использовать разные версии одного и того же макета. В основном это происходит с мобильными приложениями, в разных версиях которых используются старые API и A/B-тесты.
 В основном это происходит с мобильными приложениями, в разных версиях которых используются старые API и A/B-тесты.
В основном это происходит с мобильными приложениями, в разных версиях которых используются старые API и A/B-тесты.На этом этапе мы можем перейти к более техническим деталям:
Рисунок 10. Схема компонентов системы управления метаданными
В системе управления метаданными есть три основных уровня: серверная часть информационной модели, внешняя часть информационной модели. и бытовые услуги.
- Серверная часть отвечает за внесение изменений в метаданные, загрузку каталогов из внешних источников, выпуск новых версий.
- Внешний интерфейс отвечает за доступ в режиме реального времени к макетам, каталогам и атрибутам. Наиболее распространенные варианты использования: проверка формы для веб-сайта или мобильного устройства, сборка представления атрибутов для рекламы, сборка формы для рендеринга для веб-сайта или мобильного устройства.
- Потребительские услуги реализуют бизнес-логику. Это может быть интерфейс, мобильное приложение или внутренний сервис.

Серверная часть EAV для системы управления метаданными более или менее похожа на типичное веб-приложение. Он состоит из реляционной базы данных, одностраничного приложения и нескольких сложных ETL. Здесь вы можете управлять данными каталогов, правил и отношений, создавать макеты, создавать ветки, выпускать новые версии. Однако специфические вещи относятся к нашим внутренним инструментам, например автоматическое тестирование всей системы при внесении изменений в метаданные. Все эти выпуски новой версии информационной модели запускают ряд тестов E2E, чтобы убедиться, что наши пользователи по-прежнему могут добавлять или искать рекламу в каждой категории.
Рисунок 11. Одностраничное приложение бэкенда информационной модели
С технической точки зрения это сложное веб-приложение с большим количеством доменной логики и валидаторов. Они гарантируют, что все макеты, отношения, категории и атрибуты по-прежнему работают после применения изменений метаданных. Например, мы должны проверить, что нет циклических зависимостей, недостижимых состояний и так далее. Многое также происходит с генерацией макетов по запросу для отладки в промежуточной среде.
Многое также происходит с генерацией макетов по запросу для отладки в промежуточной среде.
Реализация управления версиями
Стоит упомянуть, как управление версиями реализовано в базе данных. Мы много изучали управление версиями и решили использовать стратегию добавления журнала. Эта стратегия означает, что всякий раз, когда мы делаем даже малейшее изменение, например, исправляем орфографическую ошибку, нам необходимо выпустить новую версию с дублированием всех сущностей: макета, каталогов и т. д.
Для реализации техники версионирования в базе данных , мы решили скопировать всю схему в Postgres со всеми сущностями для новой версии. Мы не обнаружили никаких недостатков этого подхода, за исключением того, что он замедляет работу пользовательского интерфейса инструментов, которые сканируют все схемы для их отображения и управления ими. Несмотря на то, что ограничений на количество схем почти нет, это не так важно, потому что жизненный цикл схемы для каждой версии не длится очень долго и ограничивается продолжительностью разработки версии и ее тестирования. После того, как новая версия инфомодели готова и протестирована, мы ее выпускаем. Но что означает освобождение?
После того, как новая версия инфомодели готова и протестирована, мы ее выпускаем. Но что означает освобождение?
Что происходит на этапе выпуска
Мы выпускаем новую версию инфомодели, когда уверены, что применили все изменения и готовы запустить ее в производство.
Для запуска новой версии в производство мы запускаем сервисы валидаторов и серию E2E-тестов. Они проверяют выпуск новой версии метаданных, чтобы гарантировать, что она не будет семантически разрушать пользовательский опыт. Следующий шаг — сгенерировать манифесты из текущего состояния базы данных и сбросить их в хранилище статических файлов. Вот и все.
Когда клиенты требуют выпущенную версию макета, службы внешнего интерфейса обращаются к этому хранилищу манифестов и подготавливают их для обработки запросов клиентов. Эти файлы распространяются nginx с разным уровнем кэширования, например, etags. Каждый новый выпуск создает дамп новой версии и никогда не затрагивает старые версии, поскольку мы использовали только добавление версий.
Однако, когда мы хотим протестировать конкретную версию в staging, мы не делаем всех этих шагов. Вместо этого манифесты генерируются по требованию. Манифесты могут быть очень большими, поскольку некоторые из них содержат иерархические зависимости данных и могут ухудшить работу пользователя. Чтобы решить эту проблему, вопросы производительности и памяти в продакшене, мы разделяем такие манифесты на иерархические разделы. Это повышает скорость генератора по требованию и увеличивает количество попаданий в кэш для манифестов в рабочей среде.
Распространение релиза
Формат файлов json, которые сохраняются для чтения и интерпретации внешним интерфейсом, будет обсуждаться в части внешнего интерфейса. На данный момент стоит отметить, что они никогда не удаляются, а также разбиваются на отдельные части в целях оптимизации для внешних служб. Хранилище обеспечивает легкий доступ ко всем версиям инфомодели, которые когда-либо были выпущены, и мы не беспокоимся о том, что кто-то запросит абсолютные или старые версии, они всегда будут доступны. После выполненного релиза мы архивируем схему базы данных этой версии.
После выполненного релиза мы архивируем схему базы данных этой версии.
Внешние службы — это базы данных только для чтения со встроенным пользовательским интерпретатором для их упрощенного DSL. Существует три службы: служба компоновки, служба механизма правил и служба создания URL-адресов. Однако из-за архитектуры всей системы они имеют много общих деталей реализации и свойств. Давайте сначала посмотрим на диаграмму компонентов для служб внешнего интерфейса:
Рисунок 12. Диаграмма компонентов для служб внешнего интерфейса
Может показаться, что службы действуют как прокси перед хранилищем. Но это не так, потому что файлы метаданных, находящиеся в хранилище, сами по себе не имеют смысла. Во-первых, вы должны «скомпилировать» файлы метаданных, чтобы выполнять к ним запросы. Кроме того, у сервисов нет нагрузки на запись, и они действительно услуги без гражданства . Это свойство дает нам Неограниченное горизонтальное масштабирование ( по крайней мере, пока сети кластеров k8s не лопнут).
Рисунок 13. Диаграмма потока запросов
Диаграмма потока запросов показывает нам, что службы внешнего интерфейса делают внешние исходящие запросы только в том случае, если запрошенный макет отсутствует в кеше. Это единственный случай, когда нам нужны внешние запросы, в противном случае сервис отвечает на запрос из внутреннего кеша в памяти. Исходящие запросы происходят редко. Они происходят при выпуске новой основной ветки инфомодели, запуске новых A/B-тестов или развертывании сервисов. Но сначала мы должны поговорить о кэшировании.
Освобождение кэша
Сколько макетов экземпляр может хранить в памяти одновременно? В реальном мире ответ — это зависит. Наиболее важными причинами являются количество зависимостей между атрибутами, которые превращаются в объемы ОЗУ, занимаемые службой. Самая глубокая категория Авито с большим количеством атрибутов и взаимозависимостей между ними — категория авто. Только посмотрите на количество зависимостей только для производителя автомобилей Acura:
Рисунок 14. Количество узлов и зависимостей между атрибутами
Количество узлов и зависимостей между атрибутами
На данный момент ясно, что мы не можем позволить себе хранить все макеты в памяти. Мы не можем этого сделать из-за огромного размера и постоянно меняющегося количества макетов из-за A/B-тестов и пошаговой разработки системы. Мы должны использовать ограничение, которое представляет собой количество макетов, которые мы можем хранить в памяти одновременно:
Рисунок 15. Использование слота кэш-памяти. Зеленая линия — это выпуск новой версии сервиса
. Однако в нашем случае мы не можем просто использовать стратегию LRU или LFU для вытеснения раскладок. Причина в непропорциональном использовании разных макетов. Например, верстка для проверки подачи новой рекламы встречается на пару раз реже, чем верстка показа атрибутов на странице с рекламой:
Чтобы решить эту проблему, мы выбрали кэш ARC. Кэш Arc отслеживает частоту и давность использования определенного макета. Это помогает не вытеснять макеты, которые получают относительно мало запросов в секунду, но также очень важны. Примером такого макета является отправка нового объявления, которое имеет небольшое количество запросов, но очень важно иметь его в кеше из-за важности не пропустить отправку формы пользователем.
Примером такого макета является отправка нового объявления, которое имеет небольшое количество запросов, но очень важно иметь его в кеше из-за важности не пропустить отправку формы пользователем.
Прогрев кеша
Всякий раз, когда мы развертываем группу экземпляров интерфейсных служб в рабочей среде, они запускаются с пустым кешем. Разогрев на реальных запросах пользователей — плохой опыт для наших потребителей, потому что это может закончиться неудачным запросом на отправку нового объявления. Поэтому мы придумали стратегию разогрева.
Каждая служба знает, что находится в ее кеше в памяти. Таким образом, экземпляр выгружает список макетов в памяти в кластер Redis.
Рисунок 17. Процесс прогрева кэша в памяти
Процесс развертывания выглядит следующим образом:
- Мы используем стратегию скользящего обновления, которая позволяет нам распределять нагрузку, когда мы чрезмерно загружаем спецификации макетов.
- Экземпляр переходит к кластерам Redis и получает список используемых в данный момент макетов. После этого он подтверждает собственное успешное развертывание, предоставляя балансировщикам нагрузки k8s проверку работоспособности 200.
- Служба просматривает список и загружает макеты так же, как и при промахах кеша. Если что-то пойдет не так, экземпляр пропускает этот процесс.
- После всего этого служба сообщает k8s, что готова обрабатывать запросы.
 После этого он подтверждает собственное успешное развертывание, предоставляя балансировщикам нагрузки k8s проверку работоспособности 200.
После этого он подтверждает собственное успешное развертывание, предоставляя балансировщикам нагрузки k8s проверку работоспособности 200.Рисунок 18. Прогрев кэша перед получением запросов инстансами
Зеленая пунктирная линия на рисунке показывает, когда новые инстансы получили запросы от балансировщика нагрузки. Пик до этого показывает, сколько времени ушло на прогрев конкретного макета. Запуск примерно 60 экземпляров занимает около четырех минут.
Система управления метаданными является неотъемлемой частью высоконагруженной секретной системы. В нашем случае это помогает проводить A/B-тесты любых изменений метаданных, настраивать SEO и значительно сокращать время выхода на рынок для запуска функций, связанных с метаданными. Нам потребовалось много работы, чтобы создать нашу текущую систему, и мы все еще с нетерпением ждем новых улучшений. Тем более, что эта система вызвала много запросов от внутренних команд, которые активно используют ее ежедневно, есть много работы для улучшения!
Тем более, что эта система вызвала много запросов от внутренних команд, которые активно используют ее ежедневно, есть много работы для улучшения!
9Технологический блог 0000 от Avito: встречайте нас на Medium! | от АвитоДев | AvitoTech
Всем привет, сегодня мы запускаем блог Avito о технологиях на Medium. Для начала несколько слов об Авито. Avito — это платформа онлайн-объявлений как для частных лиц, так и для компаний. В настоящее время Avito стабильно входит в топ-5 российских сайтов и в топ-3 мировых сайтов объявлений по разным данным. Вещи, выставленные на продажу на Авито, могут быть как новыми, так и бывшими в употреблении. На сайте также публикуются вакансии и резюме.
В этом блоге мы расскажем вам о технологиях, лежащих в основе платформы Авито. Начнем с нескольких слов о текущем состоянии проекта, функциях его инженерной команды и наших планах на ближайшее будущее.
Как и многие другие крупные проекты, Avito был запущен небольшой командой. Первая версия сайта была запущена еще в 2007 году, и первые шаги шли методом проб и ошибок. В своем нынешнем виде сайт появился лишь два года спустя. Веб-сервис изначально разрабатывался командой всего из 4 разработчиков, которые занимались абсолютно всем — от инфраструктуры до фронтенда. 2009 годверсия веб-сайта определенно не была чем-то, что можно было бы рассматривать для участия в конкурсе на лучший дизайн веб-сайта. Но те, кто участвовал в проекте, до сих пор испытывают по нему ностальгию. И гордитесь этим, потому что проект был реализован с ограниченными ресурсами, и все же ему удалось заявить о себе и заложить основу успешного бизнеса.
В своем нынешнем виде сайт появился лишь два года спустя. Веб-сервис изначально разрабатывался командой всего из 4 разработчиков, которые занимались абсолютно всем — от инфраструктуры до фронтенда. 2009 годверсия веб-сайта определенно не была чем-то, что можно было бы рассматривать для участия в конкурсе на лучший дизайн веб-сайта. Но те, кто участвовал в проекте, до сих пор испытывают по нему ностальгию. И гордитесь этим, потому что проект был реализован с ограниченными ресурсами, и все же ему удалось заявить о себе и заложить основу успешного бизнеса.
Трудно представить, но до 2012 года размер команды разработчиков не менялся. Однако проект разрастался, и мы чувствовали потребность в новых талантах. В 2012 году команда вступила в фазу экспоненциального роста. Оно стало подразделяться на специализации, направления, проекты, команды и группы. Сейчас в Авито есть целый инженерный отдел, в котором работает более 300 специалистов.
Через веб-приложения и мобильные приложения платформа ежемесячно обслуживает более 35 миллионов пользователей, которые ежедневно добавляют около миллиона новых объявлений (в бэк-офисе накоплено более миллиарда объявлений) и совершают более 100 000 транзакций. По данным Яндекса, в некоторых городах России (например, в Москве) Авито считается высоконагруженным проектом по просмотрам страниц. Некоторые цифры могут дать лучшее представление о масштабах проекта: 300+ серверов, >20 ТБ в Postgres, 270 ТБ изображений, 13 Гбит/сек трафика в вечерние часы пик, около миллиона запросов в минуту к бэкенду. Поэтому опыт обработки данных имеет решающее значение для наших бизнес-процессов. При этом эти объемы данных нужно не только накапливать и хранить, но и обрабатывать, фильтровать, классифицировать и делать доступными для поиска.
По данным Яндекса, в некоторых городах России (например, в Москве) Авито считается высоконагруженным проектом по просмотрам страниц. Некоторые цифры могут дать лучшее представление о масштабах проекта: 300+ серверов, >20 ТБ в Postgres, 270 ТБ изображений, 13 Гбит/сек трафика в вечерние часы пик, около миллиона запросов в минуту к бэкенду. Поэтому опыт обработки данных имеет решающее значение для наших бизнес-процессов. При этом эти объемы данных нужно не только накапливать и хранить, но и обрабатывать, фильтровать, классифицировать и делать доступными для поиска.
Ни один инструмент не может эффективно справиться с этими задачами, поэтому Avito использует ряд решений, таких как: PostgreSQL (установка PostgreSQL от Avito — одна из крупнейших и справляется с одними из самых высоких нагрузок в мире), Tarantool, Vertica, MongoDB, Redis и другие системы хранения. Об архитектуре системы мы расскажем в следующих постах.
Тонны данных хороши для платформы, но представляют собой проблему для пользователя, который хочет найти именно то, что ему нужно. На помощь пользователю приходят инструменты классификации и поиска объявлений. Поиск — самая сложная задача. Проблема не столько в объеме данных, сколько в человеческом факторе. Реальность такова, что пользователи всегда ошибаются, как в текстах объявлений, так и в поисковой строке. Одна из основных задач — устранить ошибки в объявлениях и понять, что имел в виду пользователь.
На помощь пользователю приходят инструменты классификации и поиска объявлений. Поиск — самая сложная задача. Проблема не столько в объеме данных, сколько в человеческом факторе. Реальность такова, что пользователи всегда ошибаются, как в текстах объявлений, так и в поисковой строке. Одна из основных задач — устранить ошибки в объявлениях и понять, что имел в виду пользователь.
Для устранения ошибок используются всевозможные справочные материалы и алгоритмы коррекции, а также более продвинутые подходы, такие как компьютерное зрение. Например, компьютерное зрение способно с очень высокой вероятностью (в некоторых категориях выше 95%) проверить, правильно ли пользователь выбрал категорию объявления. Кроме того, Avito регулярно отправляет специалистов по машинному обучению на конкурсы (проводимые такими платформами, как machinelearning.ru, boosters и kaggle), целью которых является поиск наиболее эффективных алгоритмов для решения различных прикладных задач.
Для полнотекстового поиска используется Sphinx, с которым мы регулярно делимся опытом и активно участвуем в развитии технологии.
Как уже было сказано, ежедневно пользователи добавляют около миллиона новых объявлений. Но мало кто знает, что больше половины из них — спам. Традиционно модерация использовалась для выявления спама. Забавный факт: первая версия системы модерации была написана всего за неделю, и она настолько эффективна, что с тех пор не потребовалось ни одного крупного обновления. Но, несмотря на улучшения, очевидно, что вручную обрабатывать такой объем информации невозможно. Поэтому используются более продвинутые методы, например, нейронные сети, которые непрерывно обучаются на основе решений модератора-человека.
Данные — не единственная проблема. Рынок постоянно диктует новые требования, которые выливаются во все более сложную бизнес-логику. Исторически бизнес-логика платформы реализована на PHP. В 2016 году мы перешли на новую версию — PHP 7, и серверы взяли передышку, нагрузки упали в три раза. Сегодня PHP — не единственный серверный язык, используемый на Авито. Изначально проект имел монолитную архитектуру, но уже давно движется в сторону микросервисов. В зависимости от задачи и нагрузок используются разные языки, такие как Python и Go.
В зависимости от задачи и нагрузок используются разные языки, такие как Python и Go.
Какими бы сложными ни были задачи на стороне сервера, все это скрыто от пользователя. За то, что видят пользователи при взаимодействии с сервисом, отвечает команда фронтенда. Изначально сайт строился с использованием доступных на тот момент технологий серверного рендеринга и jQuery. Но не так давно мы полностью отказались от jQuery в пользу браузерных API и небольших библиотек, решающих конкретные задачи. Frontend-разработка старается идти в ногу со временем, использовать новейшие технологии и решения. Например, сразу после утверждения спецификаций была внедрена новая версия JavaScript (сейчас используется ECMA2016). Кроме того, появляются новые веб-приложения (SPA), построенные на React и base.js. Фронтенд-разработчики также принимают участие в проектах с открытым исходным кодом (таких как CSSO (CSS Optimizer — минимизатор CSS со структурными оптимизациями), разрабатывают инструменты и делятся своим опытом на конференциях.
Avito появился в момент зарождения мобильной платформы, какой мы ее знаем сегодня. Естественно, все началось с веб-версии, затем была запущена веб-версия для мобильных устройств. Но нативные приложения имеют функции, зависящие от платформы. Сегодня мобильные приложения находятся в центре внимания. Отдельные команды одновременно разрабатывают несколько приложений для iOS и Android. Ребята очень серьезно относятся к своей миссии, делятся опытом на конференциях и на GitHub. Один из их проектов — медиа-сборщик Avito Paparazzo, который мы разместили в прошлом году и о котором вы могли прочитать на сайте maniacdev.com или в технологическом блоге OLX Group.
Обе команды мобильных разработчиков — iOS и Android — используют передовые технологии. Во-первых, это Kotlin (который мы начали использовать еще до выхода версии 1.0) и Swift. Они почти полностью заменили наследие Java и Objective-C в наших продуктах. Во-вторых, мы инвестируем в разработку и продвижение лучших инженерных практик — CI, CD, Code Review и автоматизация тестирования. В-третьих, это слабосвязанная масштабируемая архитектура, которая позволяет нескольким группам разработчиков слаженно работать над большим проектом и оперативно реагировать на запросы пользователей.
В-третьих, это слабосвязанная масштабируемая архитектура, которая позволяет нескольким группам разработчиков слаженно работать над большим проектом и оперативно реагировать на запросы пользователей.
Изначально в Avito не было функции тестирования, а первые QA-специалисты присоединились к команде в 2012 году. Сегодня у нас более 40 специалистов, треть из них специализируется на автоматизации. Инструментарий стандартный: PHP + PHPUnit, Selenium. У нас есть система запуска тестов, через которую проходит в среднем 110–120 тысяч тестов в день. На пике эта цифра достигает 200 000. Для организации взаимодействия между тестировщиками и разработчиками используется собственная система управления тест-кейсами, позволяющая хранить тест-кейсы, выполнять их и прикреплять баги в Jira.
Так устроена разработка на Авито, короче говоря. Конечно, многое остается за кадром. Мы постараемся восполнить этот пробел в ближайшее время.
Узнайте больше о внутренней работе Avito из статей в технологическом блоге OLX Group:
- Vertica + Anchor Modeling = Вырастите свой мицелий;
- Папараццо.